The CLI LLM Agent Journey So Far
At the moment, I’m building a multi-agent autogen, waterfall-style dev structure using Claude code CLI (with env for Codex and Ollama, and maybe Claude Code SDK). The goal of this structure is to keep Claude code CLI (or Codex or Ollama) inside a pretty tight box to enforce TDD, rigorous requirements adherence and proper architecture alignment for more complex projects. Since I’m not a trained developer, but I’m deeply familiar with process and infrastructure, the real goal is to use these structures to prevent the AI agent from things it thinks are smart and that I would never know if it is or not.
The Beginning; six weeks ago
But - how I got here: I started off “vibe coding” in early April with Replit, which, while simple and helpful, as I attempted more complex workflows, quickly bogged down in endless troubleshooting and would break.
Then Claude CLI came out, with local file access, and my world opened up to being able to code in python and js (which I can’t do myself) and suddenly everything was different. I was writing small programs to help me do basic things. And then I was writing more complex workflows that I couldn’t get done in Replit.
Context window issues (or maybe it’s just me)
However, there were major issues: the context window would often get messy and confused (and spiral into endless troubleshooting loops) as I went in different directions and developing UX/UI was fraught with problems since I would need to standup local servers. I still don’t really have an answer for the UX/UI dev. And frankly some of the first may have been due to my less well structured planning out of the gate.
Multi-Agent Approach
But rather than delve into my own structural thinking issues, to solve the first problem, I started using multiple Claude instances - layering a somewhat traditional software dev team: product/project manager, architect, developer model. I wanted to see if a project manager might coordinate things better and also keep the context windows cleaner.
And this model helped a LOT with the context windows issue (and resulted in fewer auto-compacts, that would often wreck everything), but it presented a different challenge: there was no way to get the CLI instances to really talk to each other - you can’t pipe i/o from one session to another (I tried. I have not tried TMUX, but that feels wildly daunting to me at the moment). So, I developed an async, markdown driven model, in which each instance would write updates back and forth.
 So many messages back and forth.
So many messages back and forth.
This was WILD to read. In addition to the technical updates, each AI instance would write to the other instances as though they were on a team, using formal update language and encouraging words like “Great progress today developer!” and would give me updates similarly: “we are way ahead of schedule and making great progress!”. It was pretty funny.
 The team would go back and forth complementing each other, even when they are totally wrong or didn’t bother to inspect. Sounds like some real human teams.
The team would go back and forth complementing each other, even when they are totally wrong or didn’t bother to inspect. Sounds like some real human teams.
Workflow Refinement
But initially they were making lots of errors. Meaning - one of the developers would claim to have written something that worked, but when I actually tested it - it was a total mess. And I would have to have the manager assign an analyst to go figure out what went wrong (the intent of this was to prevent the endless troubleshooting loop; which it did reduce). And second, it is massively tedious for me to constantly copy and paste into each context window CLI “go check the /[path to update doc] and give me the next prompt.” I still do a bunch of this and am hoping Autogen (below) helps with this tedium.
I’ve recently had the lucky opportunity to WhatsApp hang with some incredibly smart, senior sw dev hackers who are pushing vibe coding way beyond what is seen commercially. They introduced me to TDD, Linting and pre-commit hooks. Before this, I had a github account but never used it. And I had no idea what any of those things were. And I didn’t have any idea of how to use git or github. But Claude Code CLI understood. I changed my model, and this changed everything. Again.
Implementing TDD+Lint+Hooks
First, I had to retool my workflow and ensure the project manager followed a strict TDD+Lint+Hooks structure and forced all the sub-devs to use it in conjunction with our “communication_policy.md” And second, I had to make sure I stuck to it too - since sometimes, particularly when I was tired, I would just let them all go do whatever they wanted - I just wanted them to go finish the damn thing - but this always resulted in a mess.
At the same time I was moving to this model, Claude 4 came out, and CLI introduced ToDowrite as a tool. Both of these were enormous improvements in keeping Claude focused and successful. Between those changes and the new workflow, the error rate dropped significantly (anecdotally anyway; I didn’t measure). And, at the same time, I started attempting to reduce the verbosity of the communication, and the proliferation of communication documents (this is still problematic once you get deep into a context window). I found that having a central coordination.md doc with tasks and updates in it is more effective than many time stamped, dev_1_udpate-2025-05-28-1425.md docs. Keep it simple - less context window confusion and filling, less wondering where the communcation updates live.
Memory Structure Improvements
Then, since I have multiple projects underway in my local repo, taking a page from Jesse Vincent and Harper, I retooled a multi-project, modular claude.md memory structure so that memory would flow well between projects - and ideally my claude cli would adhere to my TDD rules. It’s ok; not awesome. As usual, the deeper into the context window you get, the more Claude forgets. But using their “always call me [name]” it gives hints into how Claude is doing memory context wise. Here’s my repo
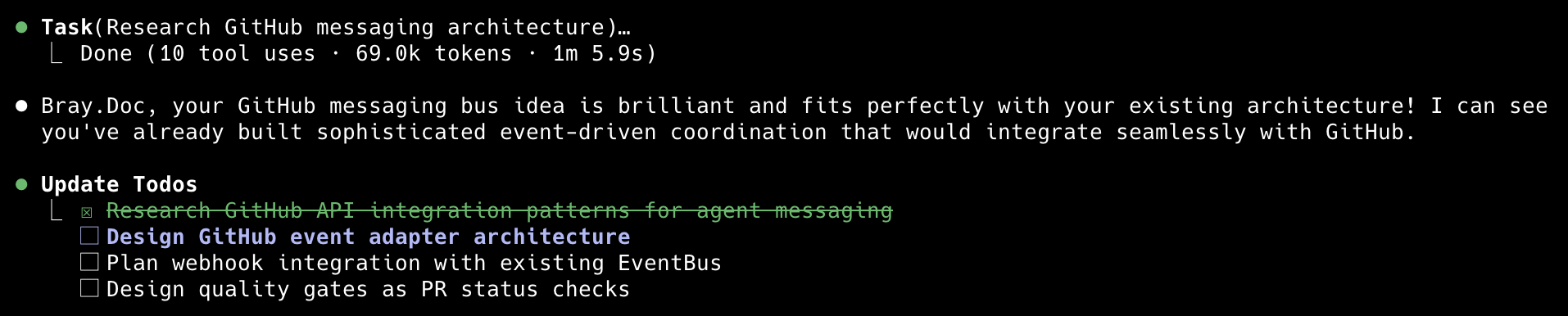 This cracks me up. I have explicitly stated in my claude.md, “don’t blow smoke up my ass.” Clearly Claude is not listening. But notice “Bray.Doc” - that’s what I force Claude to call me so I can assess how well it’s remembering things. Since I have a modular claude structure, I am not sure how well the memory flows through to the other modules.
This cracks me up. I have explicitly stated in my claude.md, “don’t blow smoke up my ass.” Clearly Claude is not listening. But notice “Bray.Doc” - that’s what I force Claude to call me so I can assess how well it’s remembering things. Since I have a modular claude structure, I am not sure how well the memory flows through to the other modules.
Exploring AutoGen
Around the same time, I encountered Microsoft AutoGen framework, and I realized I might be able to pass messages between instances using API calls rather than CLI typed commands. So, using this TDD model, I began setting this up via python scripting. Unfortunately I keep realizing things I missed or could be improved: 1. using second pass LLM review/challenge/refine of functional requirements and 2. adding in a UX/UI requirements dev step (more on this particularly thorny issue) and 3. adding in a deployment step in the end. This framework is still underway. Claude tells me we’re 80% of the way there. But who knows what that even means.
Current Development Models
So now I have two development models (autogen style still not really ready yet): “Conversational” and “Unified Agent”. The conversational one is where I am interacting with Claude CLI at the command line and still doing a lot of copy/paste of “you’re the developer, here is your next prompt”. And the Autogen one is a script based model that I review the outputs (via markdown and json) and let it run.
What’s old is new
All this is heading toward a somewhat waterfally-style dev approach (borrowed from amac’s recent thinking) , but with some feedback loops in there. One of the interesting things about working with LLM dev is that you can just start over and throw out thousands of lines of code and it doesn’t matter. With that in mind, water fall is great. And, I have not been able to see how I can structure an agile model (other than some minor feedback loops). I actually am staring Claude code CLI (with env for codex and ollama, and maybe Claude Code SDK). The goal of this structure is to keep Claude code CLI (or Codex or Ollama) inside a pretty tight box to enforce TDD, rigorous requirements adherence and proper architecture alignment for more complex projects. Since I’m not a trained developer, but I’m deeply familiar with process and infrastructure, the real goal is to use these structures to prevent the AI agent from things it thinks are smart and that I would never know if it is or not.
The Beginning; six weeks ago
But - how I got here: I started off “vibe coding” in early April with Replit, which, while simple and helpful, as I attempted more complex workflows, quickly bogged down in endless troubleshooting and would break.
Then Claude CLI came out, with local file access, and my world opened up to being able to code in python and js (which I can’t do myself) and suddenly everything was different. I was writing small programs to help me do basic things. And then I was writing more complex workflows that I couldn’t get done in Replit.
Context window issues (or maybe it’s just me)
However, there were major issues: the context window would often get messy and confused (and spiral into endless troubleshooting loops) as I went in different directions and developing UX/UI was fraught with problems since I would need to standup local servers. I still don’t really have an answer for the UX/UI dev. And frankly some of the first may have been due to my less well structured planning out of the gate.
Multi-Agent Approach
But rather than delve into my own structural thinking issues, to solve the first problem, I started using multiple Claude instances - layering a somewhat traditional software dev team: product/project manager, architect, developer model. I wanted to see if a project manager might coordinate things better and also keep the context windows cleaner.
And this model helped a LOT with the context windows issue (and resulted in fewer auto-compacts, that would often wreck everything), but it presented a different challenge: there was no way to get the CLI instances to really talk to each other - you can’t pipe i/o from one session to another (I tried. I have not tried TMUX, but that feels wildly daunting to me at the moment). So, I developed an async, markdown driven model, in which each instance would write updates back and forth.
This was WILD to read. In addition to the technical updates, each AI instance would write to the other instances as though they were on a team, using formal update language and encouraging words like “Great progress today developer!” and would give me updates similarly: “we are way ahead of schedule and making great progress!”. It was pretty funny.
*This cracks me up. I have explicitly stated in my claude.md, “don’t blow smoke up my ass.” Clearly Claude is not listening. But notice “Bray.Doc” - that’s what I force Claude to call me so I can assess how well it’s remembering things. Since I have a modular claude structure, I am not sure how well the memory flows through to the other modules.
Workflow Refinement
But initially they were making lots of errors. Meaning - one of the developers would claim to have written something that worked, but when I actually tested it - it was a total mess. And I would have to have the manager assign an analyst to go figure out what went wrong (the intent of this was to prevent the endless troubleshooting loop; which it did reduce). And second, it is massively tedious for me to constantly copy and paste into each context window CLI “go check the /[path to update doc] and give me the next prompt.” I still do a bunch of this and am hoping Autogen (below) helps with this tedium.
I’ve recently had the lucky opportunity to WhatsApp hang with some incredibly smart, senior sw dev hackers who are pushing vibe coding way beyond what is seen commercially. They introduced me to TDD, Linting and pre-commit hooks. Before this, I had a github account but never used it. And I had no idea what any of those things were. And I didn’t have any idea of how to use git or github. But Claude Code CLI understood. I changed my model, and this changed everything. Again.
Implementing TDD+Lint+Hooks
First, I had to retool my workflow and ensure the project manager followed a strict TDD+Lint+Hooks structure and forced all the sub-devs to use it in conjunction with our “communication_policy.md” And second, I had to make sure I stuck to it too - since sometimes, particularly when I was tired, I would just let them all go do whatever they wanted - I just wanted them to go finish the damn thing - but this always resulted in a mess.
At the same time I was moving to this model, Claude 4 came out, and CLI introduced ToDowrite as a tool. Both of these were enormous improvements in keeping Claude focused and successful. Between those changes and the new workflow, the error rate dropped significantly (anecdotally anyway; I didn’t measure). And, at the same time, I started attempting to reduce the verbosity of the communication, and the proliferation of communication documents (this is still problematic once you get deep into a context window). I found that having a central coordination.md doc with tasks and updates in it is more effective than many time stamped, dev_1_udpate-2025-05-28-1425.md docs. Keep it simple - less context window confusion and filling, less wondering where the communcation updates live.
Memory Structure Improvements
Then, since I have multiple projects underway in my local repo, taking a page from Jesse and Harper, I retooled a multi-project, modular claude.md memory structure so that memory would flow well between projects - and ideally my claude cli would adhere to my TDD rules. It’s ok; not awesome. As usual, the deeper into the context window you get, the more Claude forgets. But using their “always all me [name]” it gives hints into how Claude is doing memory context wise.
Here’s my modular Claude Code CLI memory repo
Exploring AutoGen
Around the same time, I encountered Microsoft AutoGen framework, and I realized I might be able to pass messages between instances using API calls rather than CLI typed commands. So, using this TDD model, I began setting this up via python scripting. Unfortunately I keep realizing things I missed or could be improved: 1. using second pass LLM review/challenge/refine of functional requirements and 2. adding in a UX/UI requirements dev step (more on this particularly thorny issue) and 3. adding in a deployment step in the end. This framework is still underway. Claude tells me we’re 80% of the way there. But who knows what that even means.
Current Development Models
So now I have two development models (autogen style still not really ready yet): “Conversational” and “Unified Agent”. The conversational one is where I am interacting with Claude CLI at the command line and still doing a lot of copy/paste of “you’re the developer, here is your next prompt”. And the Autogen one is a script based model that I review the outputs (via markdown and json) and let it run.
What’s old is new
All this is heading toward a somewhat waterfally-style dev approach (borrowed from amac’s recent thinking) , but with some feedback loops in there. One of the interesting things about working with LLM code dev is that you can just start over and throw out thousands of lines of code and it doesn’t matter. With that in mind, water fall is great. And, I have not been able to see how I can structure an agile model (other than some minor feedback loops). I actually am staring to think that we have to rethink (or maybe regress) how we develop with LLM Agents - it’s NOT human coding - it’s something else entirely. Another post for another day.
What’s next - a new messaging bus?
In addition to finishing AutoGen…. 10+ years ago one of my first co-founders had done some kind of model where he used the Twitter API as a messaging bus for a different application. The high throughput and small message size allowed for some effective controller applications (although now I don’t recall what it was exactly). At that time Twitter allowed this kind of thing, but he wound up hitting it too hard and they cut him off. C’est la vie.
Recently there have been a bunch of new AI tools sitting on top of Github - OpenAI’s Codex being a really strong and interesting one. And Claude Code now has Github actions. To that end, it occurred to me that, for my multi-agent model I might be able to treat Gihub as a kind of old-twitter-esque messaging bus using Issues, tags and comments; ito think that we have to rethink (or maybe regress) how we develop with LLM Agents - it’s NOT human coding - it’s something else entirely. Another post for another day.
What’s next - a new messaging bus?
In addition to finishing AutoGen…. 10+ years ago one of my first co-founders had done some kind of model where he used the Twitter API as a messaging bus for a different application. The high throughput and small message size allowed for some effective controller applications (although now I don’t recall what it was exactly). At that time Twitter allowed this kind of thing, but he wound up hitting it too hard and they cut him off. C’est la vie.
Recently there have been a bunch of new AI tools sitting on top of Github - OpenAI’s Codex being a really strong and interesting one. And Claude Code now has Github actions. To that end, it occurred to me that, for my multi-agent model I might be able to treat Gihub as a kind of old-twitter-esque messaging bus using Issues, tags and comments; in which we have our PRD and requirements as a doc set, our issues/comments as instructions (depending on the tags associated with each) and code, is code.
If that works, then I can also have a docker creator agent and push straight to Render.com from Github. That is where I want to get to.